Khamis Abdul-Latif Khamis* ** , Huazhu Song* and Xian Zhong*
Formal Representation and Query for Digital Contents Data
Abstract: Digital contents services are one of the topics that have been intensively studied in the media industry, where various semantic and ontology techniques are applied. However, query execution for ontology data is still inefficient, lack of sufficient extensible definitions for node relationships, and there is no specific semantic method fit for media data representation. In order to make the machine understand digital contents (DCs) data well, we analyze DCs data, including static data and dynamic data, and use ontology to specify and classify objects and the events of the particular objects. Then the formal representation method is proposed which not only redefines DCs data based on the technology of OWL/RDF, but is also combined with media segmentation methods. At the same time, to speed up the access mechanism of DCs data stored under the persistent database, an ontology-based DCs query solution is proposed, which uses the specified distance vector associated to a surveillance of semantic label (annotation) to detect and track a moving or static object.
Keywords: Digital Contents , Ontology Formal Representation , Ontology Query Model , Ontology Storage Model
1. Introduction
The digital contents (DCs) are contents that exist in the form of digital data in terms of physical structure such as textual documents, audio files, images, video, graphics, and animation files. With the increasing demands of access to DCs data in the human’s daily life, especially the increasing in all kinds of applications ion the Web and mobile terminals, it is necessary to adopt the formal representations for DCs data and provide the corresponding query mechanism in order to locate the exact DCs data required. Therefore, the research on the DCs’ expression, storage, access, query and management should be considered in a systematic way. Most of the existing approaches to this topic have met with a lot of difficulties in the creation, representation and access of the digital content domain from the semantic web [1-3]. Although some of the approaches have had some success in preserving, analyzing and representing media data in the semantic web, some problems still exist due to lack of adequate semantic illustrations of digital data [4-6]. The root of the problems lies in digital data are produced just by the natural features rather than by the structural and semantic classification on DCs.
Therefore, the tough challenge in the DCs domain is how to find the appropriate representation methods (formal methods) and techniques to abstract the conceptual domain from the DCs object to represent the preferential DCs domain with a scalable relationship existed in DCs objects.
In this paper, a novel in-depth formal representation of DCs domain is proposed that uses the techniques of ontology-based model and semantic vector to represent the scalable relationship between the sub partitions of media object data. And we also proposed the preferential query solution by outlining basic methodology that could speed up the access mechanism of the ontology-based DCs data.
This paper is organized as follows: Section 2 analyzes the challenge in DCs representation, and classifies the DCs data into different types. The formal description of DCs data is shown in Section 3. Section 4 gives the corresponding query solution, and the query sampling and analysis are shown in Section 5. Section 6 concludes this paper.
2. Related Works
The DCs data need specific techniques and standardized ontology language in order to be represented by knowledge representation paradigm library. As it is well-known that semantic is the effective technology to let the computer or machine know the data, and ontology technology has widely been used in the different fields, including DCs field. W3C proposed the web ontology language (OWL) in 2004, which is designed to provide a common way of handling the content of Web information. Different ontology languages have been so far proposed to represent DCs data and multimedia data, such as multimedia OWL (MOWL) as the extension of OWL which can represent distinct semantics in existed ontology languages for Web-based multimedia applications [7]. There are some existing comments for OWL language to deal with digital data, e.g., OWL seems to have a lot of competency which can be used to provide formal description of the conceptual domains even for digital data, and it likely has great impact in representing digital media. The W3C Media Annotation Work Group (MAWG) has injected the standardization of digital data and media ontology concept and the classification of media objects [8]. The MAWG provides the set of properties that constitutes the new multimedia directions known as Media Ontology 1.0, which provides a list of most commonly semantic annotation properties mostly used in digital media data. The main objective of these media ontology language was to provide a standardized set of multimedia content description for ontology engineers which has the same purpose as FOAF (friend of a friend) ontology model and uses a standard specification language such as MPEG-7 to represent media ontology [9]. Moreover, in the recent researches that were mentioned above on the media data ontology, we have observed many insufficient in the methodologies to represent full features DCs data that hold such perceptual modeling with an observable media features such as (text, color, motion, and size) of the DCs domain. Many models so far have been proposed for managing semantics in DCs including storage and better access mechanism [10,11]. According to the storage mechanism of digital data, the DCs are stored in the different locations in and outside database depending on the originality and nature of the DCs data. Due to the nature of the data and the aspect of DCs, DCs data always occupy a larger capacity and more space on the storage medium, so they always need large storage media and software management tools to ensure their data access and storage performance [12]. As the people produce more DCs, the demand for storage is becoming more realistic and urgent today than ever. At the same time, storage technology is constantly being upgraded and utilized, for example, from the increase of external and internal hard drive capacity of our computers to network assistant storage drives (NSA), and to the latest global storage technology (called cloud-based storage), which stores data on to a virtual cloud platform that allows remote access to data from all over the world [13].
2.1 The Challenge about DCs Data
The DCs data involve many characteristics including their retrieval, annotation, editing, authoring, behavior (static or dynamic), size, transfer mode for publication, and distribution in some applications [14,15]. Due to the inner behavior based on the content classification of media data structure and the features characteristics of the data, the DCs ontology data are facing big challenges. Probably these two behaviors can still be organized as static mode which is based on the feature character, and dynamic character that eventually represent event or outclass motion character. The static mode of DCs ontology data is often based on the realistic feature of the media object. At this circumstance ontology technology can help us to describe the concepts and relationships of the DCs data, such as the name of data, the creator, the size, the type/file format, the acquisition conditions such as lighting conditions, color information and texture, environmental conditions as well as spatial relations and the range and type of their values [16]. And the dynamic mode of media data depends upon the event or motional character of the existing media data for the real-time event character, and the physical appearance of the media data. At this point, ontology can only be used to specify the events of particular substances/objects, and at other points it can be used to classify the motions of objects based on the real-time descriptions.
Under normal circumstances, the techniques to identify the timely event might be useful or needed to capture the entire events, either by using digital video capturing techniques which involve the motion of images data and streams of sound recordings. These behaviors of classification and characterization of real time events can provide a useful help for decision making.
Again, the use of ontology techniques can provide helpful methods of dealing with the accuracy and misinformation of DCs data. The demand for DCs data is very huge, so web developers and content creators need to support DCs data with rich explicit information. The need of substantial support of information within the multimedia research community is explained [17].
DCs ontology data typically encodes high level of specialized domain knowledge, association of the domain concept with perceptual features. Therefore, the construction of DCs ontology domain involves knowledge acquisition techniques and media interactive techniques throughout the interaction process with domain expert [18]. The construction of the DCs ontology faces many challenges as any other domain, but for the DCs data a big challenge that we are likely to face is the existence of missing some semantic information or some extra knowledge related to the construction of the DCs domain.
The aim of the DCs ontology model construction is to put the dynamic and static ontology of DCs domain together. It is well known that, the two concepts are somehow undivided when characterizing the DCs data, i.e. the event's description will always and must always be associated with the semantic annotation of media object, but the recent research has shown that about 70% of the DCs data are without annotation [19]. As we have discussed earlier that the construction of DCs ontology data requires a flexible language to describe multimedia contents, such as audio and visual features which involve the color, texture, shape, frequency spectrum, size, sound identification, etc. In the form of event domain constructions, there must be a flexible ontology language that will provide the scene description in term of structural and semantic descriptions [20].
2.2 The Classification for the DCs Data
One of the difficult parts in the construction of the DCs domain is to classify and organize the DCs data according to specifications. However, the nature of DCs data is organized into two physical states: one is the dynamic mode and the other is static mode of classifications. Therefore, this kind of classification provides a unique and complex style to determine when and how to subdivide the DCs object. We are keen to figure out the behavior of the DCs domain, that is, under what circumstances the DCs data are considered dynamic or static. The static mode of classification may appear as ordinary style that preserves the external behavior of the DCs data, rather than the dynamic mode of classification that preserves eventual changes on the time of an event.
Both static and dynamic contents hold the feature characters such as the size, file types, format, color classification, etc. Meantime, the behavior of DCs data depends upon the domain classification; if the content is classified as dynamic DCs then it will probably differ from the static DCs in the form of physical expression and logical representation. Fig. 1 represents a classification model of DCs domain.
Moreover, the static characters of media object do not always experience changes during the course of the events, while the dynamic characters do.
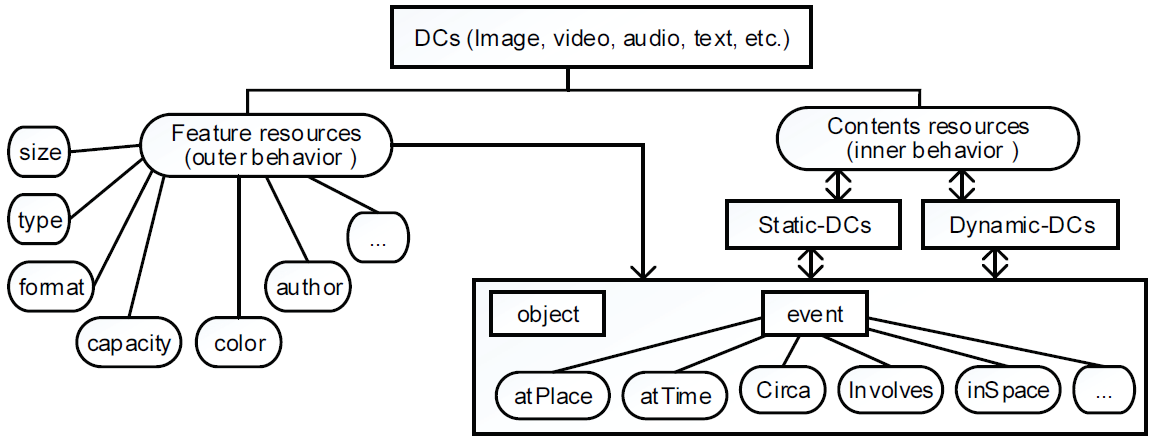
3. Formal Expression of the DCs Data
The RDF graph model and media segmentation techniques are the cornerstone for expressing the domain of DCs data, that use relational algebra to define the generic DCs features and their object relations. The RDF language provides a formal and logical support to represent DCs data, which is associated with scalable and semantic vector approach to measure the distance of relations between the nodes. The RDF languages can also conceptualize the DCs object using the logic conjunction rules to interpret multimedia data in an application context.
3.1 RDF Graph Model
The Resource Description Framework (RDF) graph model has been used as one of the formal methods to represent the ontology model for DCs domain. It can be defined as a set of triple-pattern with a subject, predicate, and object (S, P, O) for a particular media object or portion of partitioning object. To link between RDF graph model and the DCs object, five principles have been introduced in order to determine and match the ontology concept of media data,
(a) Firstly we propose the use of media segmentation technique to determine the actual events of media object by segmenting the media contents based on the regional and color classification.
(b) Discover and link the DCs entities and then map with the ontology classes so that they can be used as values for a metadata standard.
(c) Then we organize DCs data using RDF graph in order to determine the triple set of an RDF instances represented in direct label graph, i.e. if [TeX:] $$\boldsymbol{\Phi}_{R D F-t p}$$ is a set of triple pattern {s, p, o}, then each RDF instance is a member of RDF triple pattern.
(d) Any sub-graph deduced from DLG is also a subset of [TeX:] $$\boldsymbol{\Phi}_{R D F-t p}.$$
(e) For any ontology data model, class concept, relation, and instance [TeX:] $$\Phi_{R D F-t p}$$ are represented using a uniform resource identifier (URI).
To emphasis the impact of the RDF graph model of the DCs ontology data, we can now declare that: if there is any particular RDF graph model that represents ([TeX:] $$\Phi_{R D F-g}$$) then the [TeX:] $$\Phi_{R D F-g}$$ is a pair of graph model represented by edge and node which is formally represented as Eq. (1).
where [TeX:] $$N_{\text {node}}$$ is a set element belongs to all nodes in the RDF model, and [TeX:] $$E_{\text {edge}}$$ is a set of unordered pairs of an edge represented as [TeX:] $$\left\{V_{u r i}, V_{v a r}\right\} ; where by V_{u r i}$ and V_{v a r} \in N_{\text {node}}.$$ This implies that, [TeX:] $$V_{u r i} \text { and } V_{\text {var}}$$ are the subset and members of an RDF node. For example, two edges [TeX:] $$e_{1} \text { and } e_{2}$$ are said to be incident if they share a node [TeX:] $$\left(e_{1} \cap e_{2} \neq \emptyset\right)$$ and the degree of a node [TeX:] $$\operatorname{deg}\left(N_{\text {node}}\right)$$ is the number of edges incident to the nodes of RDF graphs.
Let us now consider another part of our RDF graph model, if we subdivide the DCs domain as shown in Fig. 1, such as owl:Class(object), owl:Class (event), and owl:Class(scene) classification, we will end up with many sub-graphs deduced from the top to the bottom of one generalized DCs domain, and with each sub-graph or subclass obtained, could be extended to the further domain. In other words, the RDF sub-graph has a more standardized approach of classification of conceptualization which represents DCs ontology model which has more specific properties and which could classify only one particular object. The Formal expression of Eq. (1) of the RDF graph could be extended to sub graph, such that the graph [TeX:] $$\Phi_{R D F-g}$$ can be declared as an RDF sub-graph [TeX:] $$\left(\Phi_{R D F-g}^{s u b}\right).$$ Therefore, the RDF graph is a pair of RDF sub graph model represented in Edge and Node where by each Node and Edge are also part of the RDF sub graph which is formally described as [TeX:] $$\left(N_{\text {node}}^{\text {sub}}, E_{\text {edge}}^{s u b}\right).$$ Such that,
This implies the RDF sub-graph is a subset of RDF graph in such that:
On the other hand, the RDF graph allows us to completely or partially implement certain set of rules, facts and axiomatic condition within the DCs domain. Consider the following illustration.
Let [TeX:] $$\Phi_{R D F-t p}$$be a set of triple-pattern {S, P, O} for the DCs domain whereby
In this case, the DCs ontology domain with a standardized set of subjects, properties, and objects— [TeX:] $$\mathrm{S}\left(\Phi_{\mathrm{RDF}-\mathrm{tp}}\right), \mathrm{tP}\left(\Phi_{\mathrm{RDF}-\mathrm{tp}}\right), \mathrm{O}\left(\Phi_{\mathrm{RDF}-\mathrm{tp}}\right)$$ tp)—without any rules of restriction, can promote the internal restrictions based on the nature of the Query statement executed during the retrieval of DCs data from the persistent storage. The following RDF statement is used to represent a set of triple-pattern for the DCs data bound with restriction properties that use a URI to represent class, object and relation for media object.
From a given illustration which is based on the RDF graph definition for the DCs object, it seems that the [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{tp}}$$ tpDCs-Object could also be used to represent a set of triple-pattern with restriction properties for the DCs data that contain class C, predicate P and instance of an object O of a particular class within the DCs domain. Each object within the DCs domain is given a unique URI to represent a sets of classes (owl:Class) and Relation (rdf:type). On the other hand the owl:objectProperties represent a sort of rdf:type properties which associate owl:Class to the object or instance of a class. Therefore, the owl:DataTypePropeties are the only class object properties that apply the internal restriction for the DCs data, they are used to express the restriction of class to a particular type of data format such as xsd:string, xsd:integer, xsd:date, and Time, xsd:date etc.
3.2 Media Segmentation Methods
3.2.1 The regional and color-based segmentation approach
The second part of the proposed methodology uses region and color-based segmentation approaches to differentiate and abstract entities (regions) for a particular media data. The region and color-based segmentation (RCbS) techniques are the most common media segmentation approach in the digital media domain, they can accelerate the connectivity and compactness of the object relation, utilize the regularities of boundaries between the portioned objects, and provide a uniformity in term of color and texture differentiation for the neighboring regions. The aim of segmentation is to obtain a new image in which it is easy to detect regions of interest, localize objects, or determine characteristic features of the required object.
The RCbS approach has been used in the first stage of the experiment to identify the possible number of instances within the partitioned object and which accelerates the interpretation of partitioned object based on the subjected events corresponding to the media object. The RCbS approach is used again to locate instances and boundaries of partitioned objects.
Therefore, in order to acquire a proper segmentation for the DCs data, two distinct steps were proposed:
(a) Pre-segmentation step, which is applied only when color information could determine and fulfill initial segmentation; and
(b) Syntactic-based segmentation step, which is applied only when a set of predicates could determine the set of nodes of connected components based on both color-based region classification and image annotation.
Fig. 2 represents the segmentation of digital image content, where each important feature is organized into several partitioned regions to classify the image domain.
Let [TeX:] $$\partial R$$ represent a segmented media object, [TeX:] $$\partial R_{1}, \partial R_{2}, \ldots, \partial R_{n},$$ are the sub regions obtained from partitions of connected components of media object. Therefore, the summation of imperial segmentation of media entities is given as Eq. (2).
whereby [TeX:] $$\partial R$$ is the number of regions of the segmented object [TeX:] $$\left(S_{p}\right), \text { where } p \in\{1, \ldots, m\}.$$

3.2.2 Semantic annotation
The semantic annotation is a technical method of labeling the preferential nodes of partitioned object of a DCs data. The annotation of DCs data is a process that is taken as input of an unknown content and assigns to it a label denoting its category along with a text description, which can be used to create semantic statement with a meaningful description over DCs data. This process is of great interest as it accelerates indexing, retrieving and understanding of large collections of digital contents data inside a persistent storage database.
From this level of semantic segmentation, we associate the RCbS theories with semantic annotation approach whereby each segmentation or partition object can hold at least one annotation point. This technique helps to bridge the ambiguity of the natural language when expressing notions and their computational representation in a formal language by telling a computer how the digital data objects are related and how these relations can be analyzed and evaluated automatically and algebraically.
However, it is possible for different portioned objects to occupy the same annotation. The only difference is the existence of location and position of partitioned data. If [TeX:] $$\varphi$$ indicates the total region of a media object, then
During the annotation process, most of the information needed for making the annotations is available once we partition our DCs data. Examples include author’s particular, time and date of creation. Table 1 represents the class of vocabularies that used to represent the discovered objects from partitioned data as analyzed in Fig. 3.
The goal of RCbS and annotation process is to simplify the representation of media object into something that is meaningful and easier to analyze.
Table 1.
| Class | Verbs | Remarks |
|---|---|---|
| Vehicle (CAR) | Drive, Arrive, Depart, Pass, Park, Turn, Retrace, etc. | Motion |
| Trees, Grass Plot, Garden Plot, Traffic sign, Traffic Light, Fancy | Size (Big, small) Scattered, position (Front, back, left, right), color (red, blue, white green), etc. | Non-moving |
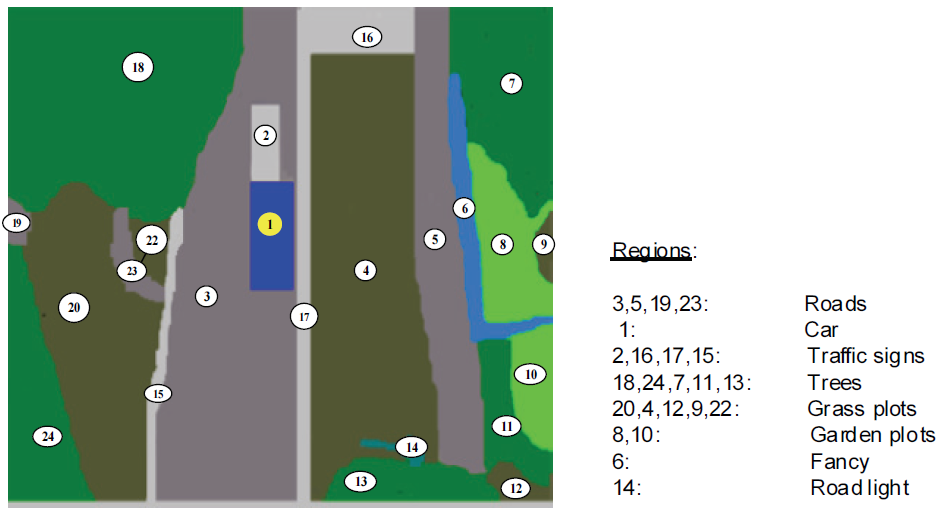
The problem may rise when the annotation information fails to provide a real interpretation for a single and or for a partitioned node, such as the distance and magnitude of a particular node or its neighboring nodes. In this case, we propose spider-net node relation (SPnR) method, which uses semantic and vector approach to compute the distance and magnitude of the nearest nodes partitions. This approach has been introduced to enhance our semantic annotations to some extent, and that can be a useful tool during the execution of semantic queries in the retrieval and storing of media data.
3.2.3 DCs node relations
The identification and the type of relations for partitioned DCs object can be classified with aspect of direction and magnitude from the neighboring nodes which could indicate the actual position and direction of the required node.
While discussing the state of partitioned object of the DCs data, proper verbs for annotation object were selected to imply a semantic labeling concept, in order for computer to easily determine relational attributes associated with the DCs data. After that we can use it to process semantic illustration based on the position of partitioned object within the required scale (direction and even magnitude of a moving or static object). However, to form all related concepts into a uniform structure, the classification of media object should be obtained first and then formulated into several regions before putting some annotation on a temporary scale.
Our main concern is to provide a proper methodology for discovering partitioned nodes of media object that has been formalized with semantic annotation. Therefore, the SPnR method uses vector methods to compute and evaluate the magnitudes and the distance relation of the partitioned object for the nearest object nodes. The node relations given in Fig. 4 is intended to find the scalable relation for the in-spot object (in-term of direction or magnitude). This technique helps us to observe many distance relations and magnitude for the most related and nearest nodes within the media object.
Fig. 4.
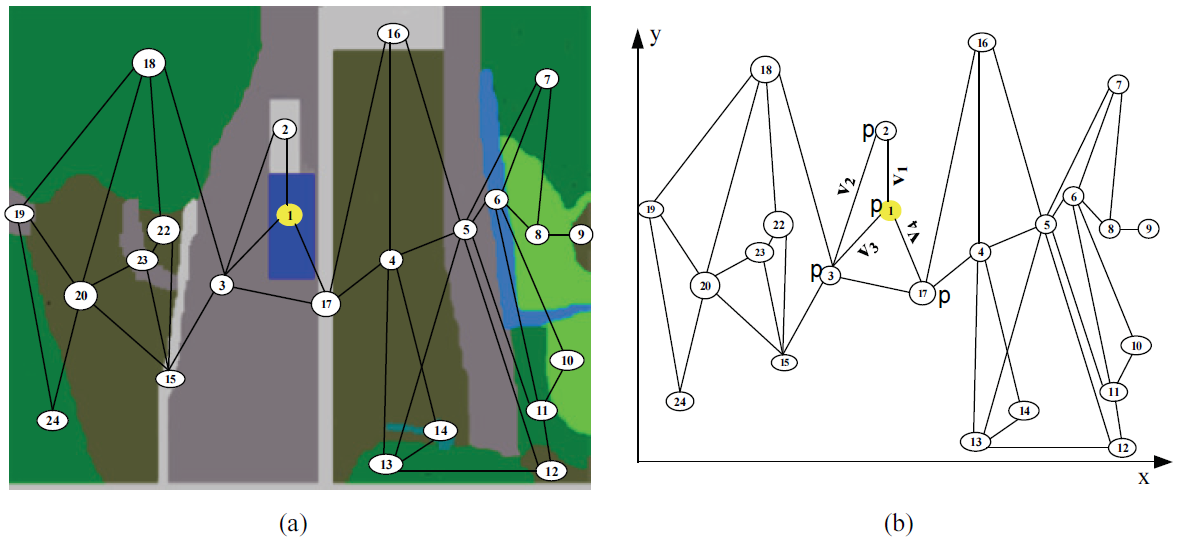
During the segmentation process, each segment is assigned to its closest partition and each partitioned object is already labeled (annotated). Therefore, the SPnR method can now be introduced to compute the distance and magnitude between one partitioned object and the closest object. We implement the SPnR method to measure the distance and compute the magnitude between two dimensional vectors for the nearest node. Fig. 4(b) provides an example of the SPnR approach.
If [TeX:] $$V_{1}, V_{2}, \ldots, V_{n}$$ represent the distance values between two points with Cartesian coordinates [TeX:] $$A_{1}\left(x_{1}, y_{1}\right)$$ and [TeX:] $$A_{2}\left(x_{2}, y_{2}\right)$$ then the following formula is applied as Eq. (3).
(3)
[TeX:] $$V_{n}=\sqrt{\left(A\left(x_{n}-x_{n-1}\right)\right)^{2}+\left(A\left(y_{n}-y_{n-1}\right)\right)^{2}}$$If we take [TeX:] $$A_{1}$$ as our focus point of relation, which is corresponding to point [TeX:] $$A_{2}, \ldots, A_{n}$$ with vector consideration, then we need to determine both magnitude and a direction of partitioned object [TeX:] $$V_{1}, V_{2},...,V_{n}.$$ To calculate the relational direction of each individual partitioned object, we must consider the relational vector V in 2-spaces that can specify the components in the A(x) and A(y) directions respectively.
Here “A” represents a set of the relation between a class/concepts for a given set of property A such that [TeX:] $$\left\{A_{1}, A_{2}, \ldots, A_{n}\right\}$$ and for a particular relational property, [TeX:] $$\mathrm{A}_{1}$$ is a focused point of scalable relation. Therefore, a given relational vector with the 2 dimensional magnitude [TeX:] $$V_{n}=\left(A_{n-1}\left(x_{n-1}, y_{n-1}\right), A_{n}\left(x_{n}, y_{n}\right)\right)$$ is calculated according to Equation (4).
(4)
[TeX:] $$|| V_{n}||=\sqrt{\left(A\left(x_{n}-x_{n-1}\right)\right)^{2}+\left(A\left(y_{n}-y_{n-1}\right)\right)^{2}}$$If [TeX:] $$A_{l}$$ represents a type of partitioned object applied for a particular subject that holds RDF data [TeX:] $$\Phi_{R D F-}p$$ Subject and[TeX:] $$A_{2}$$ represents an object relation of partition data [TeX:] $$\Phi_{R D F-p} Object,$$ to calculate the distance vector relation based on the RDF graph model shown in as Eq. (5), we deduce the various vector entities to match up with RDF graph term as Eq. (5).
(5)
[TeX:] $$|| V_{n}||=\sqrt{\left(\Phi_{R D F-P}\left(x_{n}-x_{n-1}\right)\right)^{2}+\left(\Phi_{R D F-P}\left(y_{n}-y_{n-1}\right)\right)^{2}}$$While [TeX:] $$\left(x_{n}-x_{n-1}\right) \text { and }\left(y_{n}-y_{n-1}\right)$$ represent a focus point of relational partition object. Therefore, the twodimensional points could be used to represent nodes and edges of relational partitioned data set that identifies the subject and object of RDF graph pattern. Generally, the distance relational vector between two nodes could then be represented as Eq. (6).
(6)
[TeX:] $$|| V_{n}||=\sqrt{\left(\Phi_{R D F-P}(\text {Subject})\right)^{2}+\left(\Phi_{R D F-P}(\text {Object})\right)^{2}}$$We can then compute the semantic direction of each relational object using the same vector theory shown in Eq. (7), whereby the direction of vector [TeX:] $$V_{n}$$ denoted as [TeX:] $$\theta$$ is the angle that the vector [TeX:] $$V_{n}$$ makes in the counterclockwise direction with the positive x-axis.
(7)
[TeX:] $$\tan \theta=\frac{A_{y}}{A_{x}}=\frac{A\left(y_{n}-y_{n-1}\right)}{A\left(x_{n}-x_{n-1}\right)}$$where [TeX:] $$A_{x}$$ is the horizontal change and [TeX:] $$A_{y}$$ is the vertical change in the partitioned object, and if we consider the initial and terminal point of distance, then [TeX:] $$A_{n}\left(x_{n}, y_{n}\right)$$ is the initial point, [TeX:] $$A_{n-1}\left(x_{n-1}, y_{x-1}\right)$$ is the terminal point of a chosen relation, and [TeX:] $$\theta$$ is got as Equation (8).
4. Query Methodology
Since many SPARQL query processing are more efficient to the retrieval or access of the RDF data, our intention is to enhance SPARQL query mechanism and techniques that could retrieve the DCs data particularly for partitioned nodes with RDF serialization format. For successfully achieve our study goal, the SPARQL query processing seems to have many capabilities of accessing and retrieving the DCs data more accurately, and it can also regenerate more knowledge from the existing RDF storage. Therefore, our DCs data can be stored in a fashionable and more convenient way to the retrieval systems that can energize the query processing to perform both serialization and parallel processing over parts of the data (e.g. the portioned object), and provide a faster response to the end user. Hence, a basic graph pattern (BGP) methodology is used to improve the query processing of DCs data. This gives us an opportunity to understand the correct mode of the DCs data.
4.1 Structure of DCs Query Model
The BGP can be implemented at structured level meaning that, the first step is to reengineering the query processor to work with the DCs ontology model structure. This means that the written SPARQL query must be built on and conform to the standard format of SPARQL query, and be syntactically correct and approved by query processor. A SELECT SPARQL query is expressed, and its structure resembles much with the SQL SELECT query language. Consider the following query below:
where [TeX:] $$\mu$$ is the URL of an RDF data graph G, gp is a SPARQL graph pattern and [TeX:] $$\vec{B}$$ is a RDF tuple of variables appearing in P. The following query is formulated in SPARQL structure which states that, the query must return everything from the DCs storage model.
This query evaluates the data at the structured level, where each single data in a triple statement of ([TeX:] $$\Phi_{R D F-t p} S u b j e c t, \quad \Phi_{R D F-t p} \text {Predicate}, \quad \Phi_{R D F-t p} O b j e c t$$) is evaluated, which means that each triple will be interpreted individually and return the results for all matching elements in the RDF/OWL data store. Any mistake existed in structure or syntax may result in unnecessary errors. Therefore, querying at this level means that the DCs ontology model can be interpreted as a set of triples including those elements which have been given special semantics in RDF Schema.
4.2 Query Solution
Basically, the SPARQL supports the access of DCs data with serialized format that supports BGP and sub-graph matching. The BGP theories can match against whatever is being queried and the results of matching pattern can be fed into the semantic of SPARQL.
Definition 1. The BGP of SPARQL query [TeX:] $$\left(\Phi_{\mathrm{RDF}-\mathrm{bgp}}\right)$$ is a set of triple-patterns corresponding to the RDF triple [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{tp}},$$ in which zero or more convenient DCs variables [TeX:] $$V_{\mathrm{var}}$$ might appear. A solution to a SPARQL for the [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{bgp}}$$ of DCs object is a mapping μ from the query variables in the RDF terms such that the substitution of DCs variables in the [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{bgp}}$$ would yield a subgraph of [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{g}}.$$ If [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{g}}$$ is a complex graph pattern, then [TeX:] $$\left[\Phi_{\mathrm{RDF}-\mathrm{bgp}}\right] \begin{array}{l} \Phi_{\mathrm{RDF}-\mathrm{DS}} \\ \Phi_{\mathrm{RDF}-\mathrm{g}} \end{array}$$ can be defined as given in the Table 2.
According to the formal definitions given in Table 2, it is specified that, the SPARQL of [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{g}}$$ can be recursively deduced by defining the [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{g}}$$ as follows.
Table 2.
| Definition | Operation |
|---|---|
| Graph pattern [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{bgp}}$$ | Evaluation of [TeX:] $$\left[\Phi_{\mathrm{RDF}-\mathrm{bgp}}\right]_{\Phi_{\mathrm{RDF}-\mathrm{g}}}^{\Phi_{\mathrm{RDF}-\mathrm{DS}}}$$ |
| [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{bgp}} 1$$ AND [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{bgp}} 2$$ | [TeX:] $$\left[\Phi_{\mathrm{RDF}-\mathrm{bgp}} 1\right]_{\Phi_{\mathrm{RDF}-\mathrm{g}}}^{\Phi_{\mathrm{RDF}-\mathrm{DS}}}\cap \ \left[\Phi_{\mathrm{RDF}-\mathrm{bgp}} 2\right]_{\Phi_{\mathrm{RDF}-\mathrm{g}}}^{\Phi_{\mathrm{RDF}-\mathrm{DS}}}$$ |
| [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{bgp}} 1$$ OPT [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{bgp}} 2$$ | [TeX:] $$\left[\Phi_{\mathrm{RDF}-\mathrm{bgp}} 1\right]_{\Phi_{\mathrm{RDF}-\mathrm{g}}}^{\Phi_{\mathrm{RDF}-\mathrm{DS}}}$$ OPT [TeX:] $$\left[\Phi_{\mathrm{RDF}-\mathrm{bgp}} 2\right]_{\Phi_{\mathrm{RDF}-\mathrm{g}}}^{\Phi_{\mathrm{RDF}-\mathrm{DS}}}$$ |
| [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{bgp}} 1$$ UNION [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{bgp}} 2$$ | [TeX:] $$\left[\Phi_{\mathrm{RDF}-\mathrm{bgp}} 1\right]_{\Phi_{\mathrm{RDF}-\mathrm{g}}}^{\Phi_{\mathrm{RDF}-\mathrm{DS}}} \ \cup\left[\Phi_{\mathrm{RDF}-\mathrm{bgp}} 2\right]_{\Phi_{\mathrm{RDF}-\mathrm{g}}}^{\Phi_{\mathrm{RDF}-\mathrm{DS}}}$$ |
| [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{bgp}} 1$$ FILTER C | [TeX:] $$\left\{\mu | \mu \in\left[\Phi_{\mathrm{RDF}-\mathrm{bgp}} 1\right]_{\Phi_{\mathrm{RDF}-\mathrm{g}}}^{\Phi_{\mathrm{RDF}-\mathrm{DS}}}\right. and \ \ \mu |=C\}$$ |
| [TeX:] $$\mu$$ GRAPH[TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{bgp}} 1$$ | [TeX:] $$\left[\Phi_{\mathrm{RDF}-\mathrm{bgp}} 1\right]_{\operatorname{GRP}(\mu) \Phi_{\mathrm{RDF}-\mathrm{DS}}}^{\Phi_{\mathrm{RDF}-\mathrm{DS}}}$$ |
| ?x GRAPH [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{gp}} 1$$ | [TeX:] $$U_{v \in \text { names }}\left(\Phi_{\mathrm{RDF}-\mathrm{DS}}\right)\left(\left[\Phi_{\mathrm{RDF}-\mathrm{bgp}} 1\right]_{\mathrm{GRP}(\mu) \Phi_{\mathrm{RDF}-\mathrm{DS}}} \Phi_{\mathrm{RDF}-\mathrm{DS}}\right.\cap\{\mu ? x \rightarrow v\})$$ |
Definition 2. A given RDF graph pattern [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{g}}$$ either for a simple or complex DCs model is simply known as RDF triple-pattern which is made up of single triple statement <S, P, O> or it is composed with the group of triple-pattern which is logically given as Eq. (9).
(9)
[TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{g}}:=\Phi_{\mathrm{RDF}-\mathrm{g}} | "\left(" \Phi_{\mathrm{RDF}-\mathrm{Cgp}} "\right) "$$This implies that: if [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{Cgp}}$$ is composed with a group of [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{g}},$$ then the query execution for the DCs object retrieval should hold all logical connections of each single graph with maximum logical operators such as (AND, UNION, FILTER GRAPH, OPT, etc.) then we can deduce the group of graph pattern according to Eq. (10):
(10)
[TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{Cgp}}:=\Phi_{\mathrm{RDF}-\mathrm{g}} "AND" \Phi_{\mathrm{RDF}-\mathrm{g}} | \Phi_{\mathrm{RDF}-\mathrm{g}}$ "UNION" $\Phi_{\mathrm{RDF}-\mathrm{g}} | \Phi_{\mathrm{RDF}-\mathrm{g}}$ "OPT" $\Phi_{\mathrm{RDF}-\mathrm{g}} | \Phi_{\mathrm{RDF}-\mathrm{g}}$ "FILTER" C |n "GRAPH" ФRDF-g$$where [TeX:] $$\Phi_{\mathrm{RDP}-\mathrm{rp}}$$ denotes a triple-pattern, C denotes a filter constraint, and “ | ” represents “OR” in logical operator where [TeX:] $$\mathrm{n} \in V_{\mathrm{uri}} \cup V_{\mathrm{var}}.$$ The evaluation of a SPARQLC graph pattern [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{g}}$$ over an RDF dataset [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{DS}}$$ having active graph [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{g}},$$ is denoted as Eq. (11).
(11)
[TeX:] $$\left[\Phi_{\mathrm{RDF}-\mathrm{bgp}}\right]_{\Phi_{\mathrm{RDF}-\mathrm{g}}}^{\Phi_{\mathrm{RDF}-\mathrm{DS}}} \text { or }\left[\Phi_{\mathrm{RDF}-\mathrm{g}}\right]$$When [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{DS}}$$ and [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{g}}$$ are clear from the context, then it can be recursively defined as Eq. (12).
(12)
[TeX:] $$if \(\Phi_{\mathrm{RDF}-\mathrm{bgp}} \rightarrow \Phi_{\mathrm{RDF}-\mathrm{tp}}\) then \[ \left[\Phi_{\mathrm{RDF}-\mathrm{bgp}}\right]_{\Phi_{\mathrm{RDF}-\mathrm{g}}}^{\Phi_{\mathrm{RDF}-\mathrm{DS}}}=\left\{\mu | \operatorname{dom}(\mu)=\mathrm{V}_{\mathrm{var}}\left(\Phi_{\mathrm{RDF}-\mathrm{tp}}\right) \quad \text { and } \quad \mu\left(\Phi_{\mathrm{RDF}-\mathrm{tp}}\right) \in\left(\Phi_{\mathrm{RDF}-\mathrm{tp}}\right)\right\} \]$$where [TeX:] $$\mu\left(\Phi_{\mathrm{RDF}-\mathrm{rp}}\right)$$ is the triple obtained by replacing any of the DCs variables in [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{tp}}$$ according to mapping function [TeX:] $$\mu.$$ The decision is for [TeX:] $$\Phi_{\mathrm{RDF}-\mathrm{bgp}}$$ matching without any changes or “implementation hints”. It becomes the basis of SPARQL for the DCs object retrieval.
5. Query Analysis and Sampling
Query analysis for the partitioned object is needed, especially in visual surveillance of DCs data. The essential task of the BGB query methodology is to detect and track away a moving or static object by using the specified distance vector properties with a surveillance of semantic label (annotation). It also includes the inference and techniques to represent spatial relationships of partitioned object, and finally analyze and express the events in a consistent way.
In a special dynamic scene, all visible things such as different regions, moving or static objects can be regarded as entities with their own attributes. Furthermore, these entities and their attributes can be linked to a group of given concepts. From this viewpoint, the query analysis of the underlying partitioned object is based on these classified concepts and their distance vector relationships.
Querying the partitioned data in the face of dynamic or static-based DCs object, is normally based on the query conditions that were specified in the partitioned nodes during the development process of the DCs ontology model. What is needed during the query abstraction is to find out what is the right formation that classifies the partitioned object based on dynamic or static event query criteria.
This is because different segments or partitioned objects need a unified query from different tables in the database. The point is that, once we abstract events and sub-events from partition object, each individual event is converted into the instance of class objects and classified according to the internal properties it holds, where it can create one single RDF statement.
The main advantage of event query of the DCs data is to take every DCs object with respect to the human context. The retrieval effectiveness of the events can be evaluated by using the classic information retrieval measures known as Precision and Recall. Recall is the ratio of the number of relevant records retrieved from the total number of relevant records in the database (that are not retrieved), while Precision is the ratio of the number of relevant records retrieved from the total number of irrelevant and relevant records retrieved. Table 3 gives the Precision and Recall value for spatial queries. The events query obtains a higher precision and recall than the text-based approach.
Table 3.
| S. No. | Input query | Precision | Recall | Remarks |
|---|---|---|---|---|
| 1 | The car is near the road light | 0.58 | 0.62 | Text |
| 2 | The car is 3 meters from the road light | 0.72 | 0.7 | Event |
| 3 | The car is moving fast | 0.69 | 0.65 | Event |
| 4 | The two roads are narrow | 0.55 | 0.66 | Text |
| 5 | The road is marked with traffic signs | 0.15 | 0.27 | Text |
| 6 | Trees are too near the road | 0.35 | 0.22 | Text |
| 7 | The trees are green | 0.88 | 0.43 | Text |
| 8 | The car is moving towards north | 0.78 | 0.85 | Event |
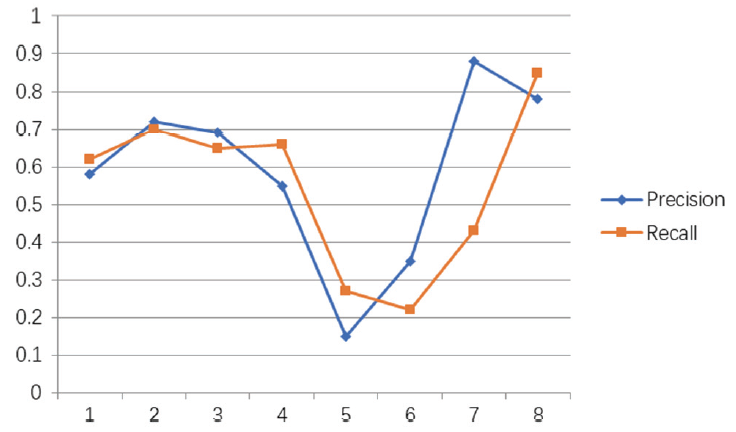
It is observed that the ontology-based event retrieval performs the event query-based techniques better than text-based query. Fig. 5 provides an evidence-based query solution for event-based query solution vise text base query solution which depends on the Precision and Recall function.
In Fig. 5, the two lines may represent the performance of the query-based solution. It is always difficult to measure and calculate the recall for data retrieval within the database, because it is very stressful to know how many relevant records exist within the database. Therefore, in this experiment we only estimate the Recall by identifying a pool of relevant records and then determine the proportion of the pool upon query retrieval and search.
6. Summary
In this paper we discuss several methods and techniques that assist us on providing a constructive methodology that re-defined the DCs data using OWL/RDF technique and media segmentation approaches. We use the vector relation approach to strengthen our semantic tactics for each DCs partitioned object. The given approaches and methodology are the core factors of this study that reengineer the query solutions for the DCs ontology data.
Acknowledgement
This paper was supported in part by the National Key Technology Research and Development Program of the Ministry of Science and Technology of China under Grant 2012BAH33F03, the National Natural Science Foundation of China under Grant 61303029, and the Natural Science Foundation of Hubei Province of China under Grant 2015CFB525.
Biography
Khamis Abdul-Latif Khamis
https://orcid.org/0000-0003-0761-4681
He was as PhD student with the School of Computer Science and Technology, Wuhan University of Technology, Wuhan, Hubei, China, whose main research interests are semantic and ontology. Now he is with the Department of Information Technology and Computer Science at the State University of Zanzibar, Zanzibar.
Biography

Biography

References
- 1 M. Budnik, E. L. Gutierrez-Gomez, B. Safadi, D. Pellerin, G. Quenot, "Learned features versus engineered features for multimedia indexing," Multimedia Tools and Applications, vol. 76, no. 9, pp. 11941-11958, 2017.doi:[[[10.1007/s11042-016-4240-2]]]
- 2 C. Cui, J. Shen, Z. Chen, S. Wang, J. Ma, "Learning to rank images for complex queries in concept-based search," Neurocomputing, vol. 274, pp. 19-28, 2018.doi:[[[10.1016/j.neucom.2016.05.118]]]
- 3 I. Rallis, N. Doulamis, A. Doulamis, A. V oulodimos, V. Vescoukis, "Spatio-temporal summarization of dance choreographies," Computers & Graphics, vol. 73, pp. 88-101, 2018.doi:[[[10.1016/j.cag.2018.04.003]]]
- 4 K. A. L. Khamis, L. Zhong, H. Z. Song, "Implementation and formalization of the digital contents’ data using OWL and DL into the reasoning modules," Applied Mechanics and Materials, vol. 644, pp. 1759-1763, 2014.custom:[[[-]]]
- 5 W. Park, M. Han, J. W. Son, S. J. Kim, "Design of scene knowledge base system based on domain ontology," in Proceedings of 2017 19th International Conference on Advanced Communication Technology (ICACT), Bongpyeong, South Korea, 2017;pp. 560-562. custom:[[[-]]]
- 6 O. O. Ergun, B. Ozturk, "An ontology based semantic representation for Turkish cuisine," in Proceedings of 2018 26th Signal Processing and Communications Applications Conference (SIU), Izmir, Turkey, 2018;pp. 1-4. custom:[[[-]]]
- 7 A. K. Rabiah, A. R. Yauri, A. Azman, "Automated semantic query formulation for document retrieval," in Proceedings of the 4th International Conference on Information Retrieval and Knowledge Management: Diving into Data Sciences (CAMP), Kota Kinabalu, Malaysia, 2018;pp. 124-131. custom:[[[-]]]
- 8 D. Cavaliere, L. Greco, P. Ritrovato, S. Senatore, "A knowledge-based approach for video event detection using spatio-temporal sliding windows," in Proceedings of 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 2017;pp. 1-6. custom:[[[-]]]
- 9 E. G. Caldarola, A. M. & Rinaldi, "Modelling multimedia social networks using semantically labelled graphs," in Proceedings of 2017 IEEE International Conference on Information Reuse and Integration (IRI), San Diego, CA, 2017;pp. 493-500. custom:[[[-]]]
- 10 N. F. Kahar, E. Izquierdo, "Ontology-based analysis of CCTV data," in Proceedings of the 7th LatAmerican Conference on Networked and Electronic Media (LACNEM), V alparaiso, Chile, 2017;custom:[[[-]]]
- 11 B. P. Singh, A. Kumar, "Conceptual roadmap of digital library content management system a semantic web approach," in Proceedings of 2018 5th International Symposium on Emerging Trends and Technologies Libraries and Information Services (ETTLIS), Noida, India, 2018;pp. 65-70. custom:[[[-]]]
- 12 M. N. Asim, M. Wasim, M. U. G. Khan, N. Mahmood, W. Mahmood, "The use of ontology in retrieval: a study on textual, multilingual, and multimedia retrieval," IEEE Access, vol. 7, pp. 21662-21686, 2019.custom:[[[-]]]
- 13 S. Laborie, A. M. Manzat, and F. Sedes, IEEE MultiMedia, 2009., https://doi.org/10.1109/MMUL.2009.68
- 14 R. A. Kambau, Z. A. Hasibuan, "Unified concept-based multimedia information retrieval technique," in Proceedings of 2017 4th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), Yogyakarta, Indonesia, 2017;pp. 1-8. custom:[[[-]]]
- 15 G. Meditskos, S. Vrochidis, I. Kompatsiaris, "Description logics and rules for multimodal situational awareness in healthcarein Multimedia Modeling. Cham: Springer, pp. 714-725, 2017.custom:[[[-]]]
- 16 O. Menemencioglu, I. M. Orak, "Semantic querying on multimedia data," in Proceedings of 2016 24th Signal Processing and Communication Application Conference (SIU), Zonguldak, Turkey, 2016;pp. 1069-1072. custom:[[[-]]]
- 17 A. Saha, M. N. Tasdid, M. R. Rahman, "Mining semantic web based ontological data," in Proceedings of 2018 21st International Conference of Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 2018;pp. 1-5. custom:[[[-]]]
- 18 A. M. Rinaldi, C. Russo, "A matching framework for multimedia data integration using semantics and ontologies," in Proceedings of 2018 IEEE 12th International Conference on Semantic Computing (ICSC), Laguna Hills, CA, 2018;pp. 363-368. custom:[[[-]]]
- 19 A. Al-Abri, Y. Jamoussi, Z. AlKhanjari, N. Kraiem, "Aggregation and mapping of social media attribute names extracted from chat conversation for personalized e-learning," in Proceedings of 2019 4th MEC International Conference on Big Data and Smart City (ICBDSC), Muscat, Oman, 2019;pp. 1-9. custom:[[[-]]]
- 20 R. A. Kambau, Z. A. Hasibuan, "Concept-based multimedia information retrieval system using ontology search in cultural heritage," in Proceedings of 2017 2nd International Conference on Informatics and Computing (ICIC), Jayapura, Indonesia, 2017;pp. 1-6. custom:[[[-]]]